Computation Layers¶
-
class
ArgmaxLayer¶ Compute the arg-max along the “channel” dimension. This layer is only used in the test network to produce predicted classes. It has no ability to do back propagation.
-
dim¶ Default
-2(penultimate). Specify which dimension to operate on.
-
-
class
ChannelPoolingLayer¶ 1D pooling over any specified dimension. This layer is called channel pooling layer because it was designed to pool over the pre-defined channel dimension back when Mocha could only handle 4D tensors. For the new, general ND-tensors the dimension to be pooled over can be freely specified by the user.
-
channel_dim¶ Default
-2(penultimate). Specifies which dimension to pool over.
-
kernel¶ Default 1, pooling kernel size.
-
stride¶ Default 1, stride for pooling.
-
pad¶ Default (0,0), a 2-tuple specifying padding in the front and the end.
-
pooling¶ Default
Pooling.Max(). Specify the pooling function to use.
-
-
class
ConvolutionLayer¶ Convolution in the spatial dimensions. For now convolution layers require the input blobs to be 4D tensors. For a 4D input blob of the shape
width-by-height-by-channels-by-num, The output blob shape is decided by thekernelsize (a.k.a. receptive field), thestride, thepadand then_filter.The
kernelsize specifies the geometry of a filter, also called a kernel or a local receptive field. Note that implicitly, a filter also has a channel dimension that is the same size as the input image. As a filter moves across the image by the specifiedstrideand optionallypadwhen on the boundary of the input image, it produce a real number by computing the inner-product between the filter weights and the local image patch at each spatial position. The formula for the spatial dimension of the output blob iswidth_out = div(width_in + 2*pad[1]-kernel[1], stride[1]) + 1 height_out = div(height_in + 2*pad[2]-kernel[2], stride[2]) + 1
The
n_filterparameter specifies the number of such filters. The final output blob will have the shapewidth_out-by-height_out-by-n_filter-by-num. An illustration of typical convolution (and pooling) is shown below: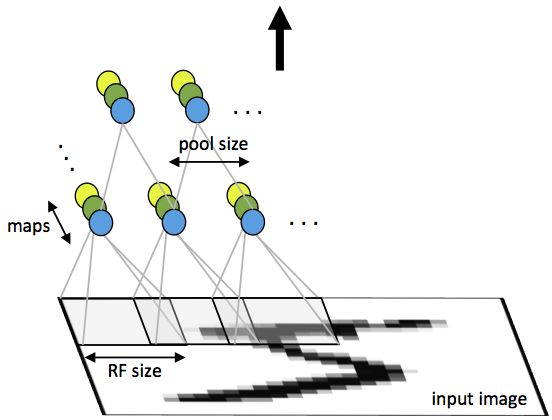
Image credit: http://ufldl.stanford.edu/tutorial/supervised/ConvolutionalNeuralNetwork/
Here the RF size is receptive field size, and maps (identified by different colors) correspond to different filters.
-
param_key¶ Default
"". The unique identifier for layers with shared parameters. When empty, the layernameis used as identifier instead.
-
kernel¶ Default (1,1), a 2-tuple specifying the width and height of the convolution filters.
-
stride¶ Default (1,1), a 2-tuple specifying the stride in the width and height dimensions, respectively.
-
pad¶ Default (0,0), a 2-tuple specifying the two-sided padding in the width and height dimensions, respectively.
-
n_filter¶ Default 1. Number of filters.
-
n_group¶ Default 1. Number of groups. This number should divide both
n_filterand the number of channels in the input blob. This parameter will divide the input blob along the channel dimension inton_groupgroups. Each group will operate independently. Each group is assigned withn_filter/n_groupfilters.
-
neuron¶ Default
Neurons.Identity(), can be used to specify an activation function for the convolution outputs.
-
filter_init¶ Default
XavierInitializer(). See initializer for the filters.
-
bias_init¶ Default
ConstantInitializer(0). See initializer for the bias.
-
filter_regu¶ Default
L2Regu(1), the regularizer for the filters.
-
bias_regu¶ Default
NoRegu(), the regularizer for the bias.
-
filter_cons¶ Default
NoCons(). Norm constraint for the filters.
-
bias_cons¶ Default
NoCons(). Norm constraint for the bias. Typically no norm constraint should be applied to the bias.
-
filter_lr¶ Default 1.0. The local learning rate for the filters.
-
bias_lr¶ Default 2.0. The local learning rate for the bias.
-
-
class
CropLayer¶ Do image cropping. This layer is primarily used only on top of data layers so backpropagation is currently not implemented. Crop layer requires the input blobs to be 4D tensors.
-
crop_size¶ A (width, height) tuple of the size of the cropped image.
-
random_crop¶ Default
false. When enabled, randomly place the cropping box instead of putting at the center. This is useful to produce random perturbations of the input images during training.
-
random_mirror¶ Default
false. When enabled, randomly (with probability 0.5) mirror the input images (flip the width dimension).
-
-
class
DropoutLayer¶ Dropout is typically used during training, and it has been demonstrated to be effective as a regularizer for large scale networks. Dropout operates by randomly “turning off” some responses. Specifically, the forward computation is
\[\begin{split}y = \begin{cases}\frac{x}{1-p} & u > p \\ 0 & u <= p\end{cases}\end{split}\]where \(u\) is a random number uniformly distributed in [0,1], and \(p\) is the
ratiohyper-parameter. Note the output is scaled by \(1-p\) such that \(\mathbb{E}[y] = x\).-
ratio¶ The probability \(p\) of turning off a response. Can also be interpreted as the ratio of all the responses that are turned off.
-
auto_scale¶ Default
true. When turned off, does not scale the result by \(1/(1-p)\). This option is used when buildingRandomMaskLayer.
-
bottoms¶ The names of the input blobs dropout operates on. Note this is a in-place layer, so
- there is no
topsproperty. The output blobs will be the same as the input blobs. - It takes only one input blob.
- there is no
-
-
class
ElementWiseLayer¶ The Element-wise layer implements basic element-wise operations on inputs.
-
operation¶ Element-wise operation. Built-in operations are defined in module
ElementWiseFunctors, includingAdd,Subtract,MultiplyandDivide.
-
tops¶ Output blob names, only one output blob is allowed.
-
bottoms¶ Input blob names, count must match the number of inputs
operationtakes.
-
-
class
InnerProductLayer¶ Densely connected linear layer. The output is computed as
\[y_i = \sum_j w_{ij}x_j + b_i\]where \(w_{ij}\) are the weights and \(b_i\) are the biases.
-
param_key¶ Default
"". The unique identifier for layers with shared parameters. When empty, the layernameis used as identifier instead.
-
output_dim¶ Output dimension of the linear map. The input dimension is automatically decided via the inputs.
-
weight_init¶ Default
XavierInitializer(). Specify how the weights \(w_{ij}\) should be initialized.
-
bias_init¶ Default
ConstantInitializer(0), initializing the bias \(b_i\) to 0.
-
weight_regu¶ Default
L2Regu(1). Regularizer for the weights.
-
bias_regu¶ Default
NoRegu(). Regularizer for the bias. Typically no regularization should be applied to the bias.
-
weight_cons¶ Default
NoCons(). Norm constraint for the weights.
-
bias_cons¶ Default
NoCons(). Norm constraint for the bias. Typically no norm constraint should be applied to the bias.
-
weight_lr¶ Default 1.0. The local learning rate for the weights.
-
bias_lr¶ Default 2.0. The local learning rate for the bias.
-
neuron¶ Default
Neurons.Identity(), an optional activation function for the output of this layer.
-
tops¶ -
bottoms¶ Blob names for output and input. This layer can take multiple input blobs and produce the corresponding number of output blobs. The feature dimensions (the product of the first N-1 dimensions) of all input blobs should be the same, but they could potentially have different batch sizes (the last dimension).
-
-
class
LRNLayer¶ Local Response Normalization Layer. It performs normalization over local input regions via the following mapping
\[x \rightarrow y = \frac{x}{\left( \beta + (\alpha/n)\sum_{x_j\in N(x)}x_j^2 \right)^p}\]Here \(\beta\) is the shift, \(\alpha\) is the scale, \(p\) is the power, and \(n\) is the size of the local neighborhood. \(N(x)\) denotes the local neighborhood of \(x\) of size \(n\) (including \(x\) itself). There are two types of local neighborhood:
LRNMode.AcrossChannel(): The local neighborhood is a region of shape (1, 1, \(k\), 1) centered at \(x\). In other words, the region extends across nearby channels (with zero padding if needed), but has no spatial extent. Here \(k\) is the kernel size, and \(n=k\) in this case.LRNMode.WithinChannel(): The local neighborhood is a region of shape (\(k\), \(k\), 1, 1) centered at \(x\). In other words, the region extends spatially (in both the width and the channel dimension), again with zero padding when needed. But it does not extend across different channels. In this case \(n=k^2\).When this mode is used, the input blobs should be 4D tensors for now, due to the requirements from the underlying
PoolingLayer.
-
kernel¶ Default 5, an integer indicating the kernel size. See \(k\) in the descriptions above.
-
scale¶ Default 1.
-
shift¶ Default 1 (yes, 1, not 0).
-
power¶ Default 0.75.
-
mode¶ Default
LRNMode.AcrossChannel().
-
class
PoolingLayer¶ 2D pooling over the 2 image dimensions (width and height). For now the input blobs are required to be 4D tensors.
-
kernel¶ Default (1,1), a 2-tuple of integers specifying pooling kernel width and height, respectively.
-
stride¶ Default (1,1), a 2-tuple of integers specifying pooling stride in the width and height dimensions, respectively.
-
pad¶ Default (0,0), a 2-tuple of integers specifying the padding in the width and height dimensions, respectively. Paddings are two-sided, so a pad of (1,0) will pad one pixel in both the left and the right boundary of an image.
-
pooling¶ Default
Pooling.Max(). Specify the pooling operation to use.
-
-
class
PowerLayer¶ Power layer performs element-wise operations as
\[y = (ax + b)^p\]where \(a\) is
scale, \(b\) isshift, and \(p\) ispower. During back propagation, the following element-wise derivatives are computed:\[\frac{\partial y}{\partial x} = pa(ax + b)^{p-1}\]Power layer is implemented separately instead of as an Element-wise layer for better performance because there are some special cases of the Power layer that can be computed more efficiently.
-
power¶ Default 1
-
scale¶ Default 1
-
shift¶ Default 0
-
-
class
RandomMaskLayer¶ Randomly mask subsets of input as zero. This is a wrapper over
DropoutLayer, but- This layer does not rescale the un-masked part to make the expectation the same as the expectation of the original input.
- This layer can handle multiple input blobs while
DropoutLayeraccept only one input blob.
Note
- This layer is a in-place layer. For example, if you want to use this to
construct a denoising auto-encoder, you should use a
SplitLayerto make two copies of the input data: one is randomly masked (in-place) as the input of the auto-encoder, and the other is directed to aSquareLosslayer that measure the reconstruction error. - Although typically not used, this layer is capable of doing
back-propagation, powered by the underlying
DropoutLayer.
-
class
SoftmaxLayer¶ Compute softmax over the “channel” dimension. The inputs \(x_1,\ldots,x_C\) are mapped as
\[\sigma(x_1,\ldots,x_C) = (\sigma_1,\ldots,\sigma_C) = \left(\frac{e^{x_1}}{\sum_j e^{x_j}},\ldots,\frac{e^{x_C}}{\sum_je^{x_j}}\right)\]To train a multi-class classification network with softmax probability output and multiclass logistic loss, use the bundled
SoftmaxLossLayerinstead.-
dim¶ Default
-2(penultimate). Specify the “channel” dim to operate along.
-
-
class
TiedInnerProductLayer¶ Similar to
InnerProductLayerbut with weights tied to an existingInnerProductLayer. Used in auto-encoders. During training, an auto-encoder defines the following mapping\[\mathbf{x} \longrightarrow \mathbf{h} = \mathbf{W}_1^T\mathbf{x} + \mathbf{b}_1 \longrightarrow \tilde{\mathbf{x}} = \mathbf{W}_2^T\mathbf{h} + \mathbf{b}_2\]Here \(\mathbf{x}\) is input, \(\mathbf{h}\) is the latent encoding, and \(\tilde{\mathbf{x}}\) is the decoded reconstruction of the input. Sometimes it is desired to have tied weights for the encoder and decoder: \(\mathbf{W}_1 = \mathbf{W}^T\). In this case, the encoder will be an
InnerProductLayer, and the decoder aTiedInnerProductLayerwith tied weights to the encoder layer.Note the tied decoder layer does not perform learning for the weights. However, even a tied layer has independent bias parameters that are learned independently.
-
tied_param_key¶ The
param_keyof the encoder layer that this layer wants to share tied weights with.
-
param_key¶ Default
"". The unique identifier for layers with shared parameters. If empty, the layernameis used as identifier instead.Tip
param_keyis used forTiedInnerProductLayerto share parameters. For example, the same layer in a training net and in a validation / testing net use this mechanism to share parameters.tied_param_keyis used to find theInnerProductLayerto enable tied weights. This should be equal to theparam_keyproperty of the inner product layer you want to have tied weights with.
-
bias_init¶ Default
ConstantInitializer(0). The initializer for the bias.
-
bias_regu¶ Default
NoRegu(), the regularizer for the bias.
-
bias_cons¶ Default
NoCons(). Norm constraint for the bias. Typically no norm constraint should be applied to the bias.
-
bias_lr¶ Default 2.0. The local learning rate for the bias.
-
neuron¶ Default
Neurons.Identity(), an optional activation function for the output of this layer.
-
tops¶ -
bottoms¶ Blob names for output and input. This layer can take multiple input blobs and produce the corresponding number of output blobs. The feature dimensions (the product of the first N-1 dimensions) of all input blobs should be the same, but they can potentially have different batch sizes (the last dimension).
-
-
class
RandomNormalLayer¶ - This is a source layer which outputs standard Gaussian random noise.
-
tops¶ List of symbols, specifying the names of the noise blobs to produce.
-
output_dims¶ List of integers giving the dimensions of the output noise blobs.
-
batch_sizes¶ List of integers the same length as
tops, giving the number of vectors to output in each batch.
-
eltype¶ Default
Float32.
-